
フロントエンド
Ollama
Windows/Mac/Linux対応、NVIDIA/Radeon両方対応。オープンソース?
https://ollama.com/
参考記事: https://qiita.com/s3kzk/items/3cebb8d306fb46cabe9f
ollama create elyza:jp8b -f Modelfile ollama run elyza:jp8b
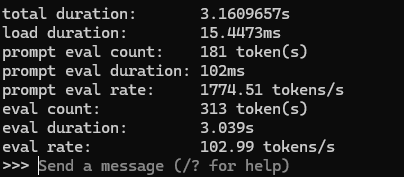
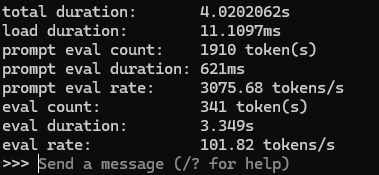
プロンプト上で「/set verbose」でTokens/secondを計測できる
モデルは Llama-3-ELYZA-JP-8B ( https://prtimes.jp/main/html/rd/p/000000046.000047565.html )、Modelfileは先の参考記事さんコピペ
llmフロントエンドとはOllamaのようなソフトウェアを意味します。llmフロントエンドを5つ列挙してください。
LLMフロントエンドは、ユーザーがLLMと対話するためのインターフェースやソフトウェアを指します。以下に、Ollamaのような
LLMフロントエンドを5つ列挙します。
- Ollama: LLMの入力と出力を処理し、ユーザーがLLMと対話するためのインターフェースを提供するソフトウェア。
- LLaMA UI: Meta AIが開発したLLMフロントエンドで、ユーザーがLLMに質問や入力を行い、結果を受け取ることができます
。- Rasa NLU: RasaはオープンソースのLLMフロントエンドで、自然言語理解(NLU)を活用してユーザーの入力を解析し、適切
な出力やアクションを実行します。- Microsoft Bot Framework: Microsoftが提供するLLMフロントエンドで、ボットやアプリケーションに自然言語処理
(NLP)や機械学習の能力を組み込みます。- Dialogflow ES: Google Cloudが提供するLLMフロントエンドで、ユーザーの入力と出力を処理し、LLMとの対話を可能にし
ます。
モデル
ベンチマークの基準はOpenAIのGPT3.5、GPT4oなど、主要バージョンと比較する雰囲気。まずはローカルLLM方面色々試す。
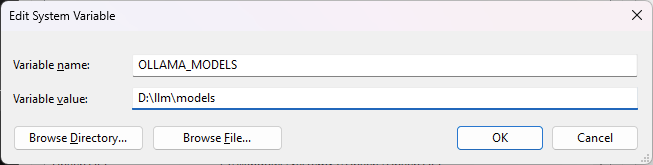
ollamaのモデル保存場所を変更する
llma3.2-vision
https://ollama.com/library/llama3.2-visionollama pull llma3.2-vision
11b: RTX4090+32GBで動く、90b厳しい(VRAM60GBは必要)
Debian 12 (bookworm, 12.9) + Radeon 6700XT
公式のインストール方法を利用。Debian12対応。
Proxmox(12700k)のguest(8core, 20GB)にPCIE rawで6700XTをパス。host側にRadeon関連は入れておらず、Proxmox既定状態。

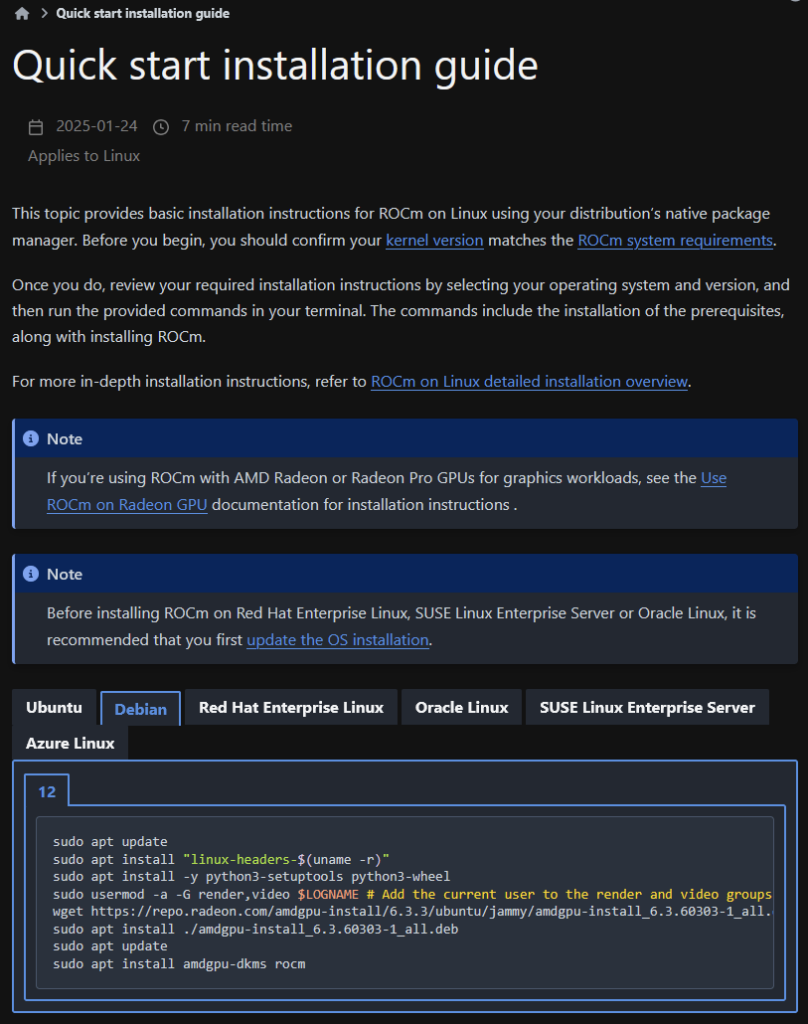
kernelモジュールコンパイルのためか、結構なディスク容量を使う。インストール中やけど、既に36GB使ってる。
ollama linuxバージョンを公式のcurl使うコマンドで入れたら、素直にAMD Gpuを認識した。
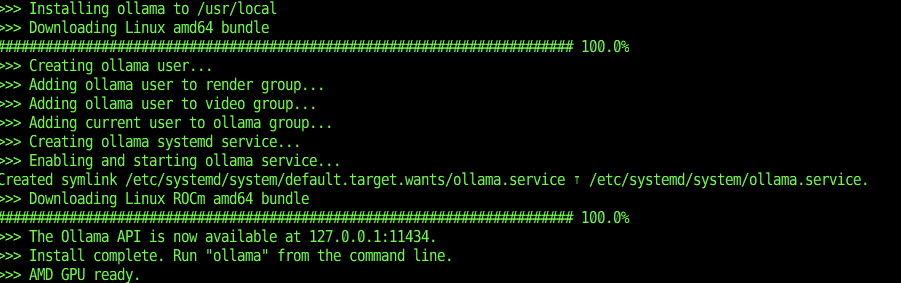
6700XTはRoCMのドライバは入るものの、やはり、サポートリストにないためか、elyzaはGPU使ってくれず。

Cyberagent DeepSeek-R1
参考: https://note.com/catap_art3d/n/n523e1fe9bfee
利用するggufモデル: https://huggingface.co/mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf
まず、Modelfile作るために参考記事のとおり、ollama deepseek-r1をpullする
ollama deepseek-r1:14b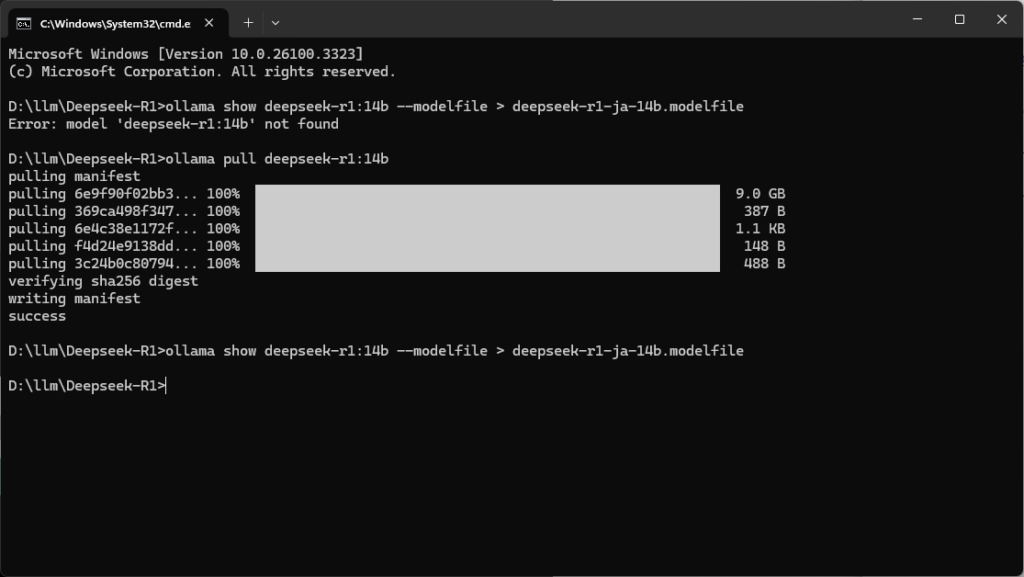
それから、参考記事のとおり、Modelfileを抜き出す。
編集する ※下のコピーしても動くと思うけど、参考記事通りの手順推奨
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this, replace FROM with:
# FROM deepseek-r1:14b
FROM cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-Q8_0.gguf
TEMPLATE """{{- if .System }}{{ .System }}{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1}}
{{- if eq .Role "user" }}<|User|>{{ .Content }}
{{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }}
{{- end }}
{{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }}
{{- end }}"""
PARAMETER stop <|begin▁of▁sentence|>
PARAMETER stop <|end▁of▁sentence|>
PARAMETER stop <|User|>
PARAMETER stop <|Assistant|>
LICENSE """MIT License
Copyright (c) 2023 DeepSeek
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
"""
ollamaモデル作成
ollama create deepseek-r1-ja-14b -f deepseek-r1-ja-14b.modelfile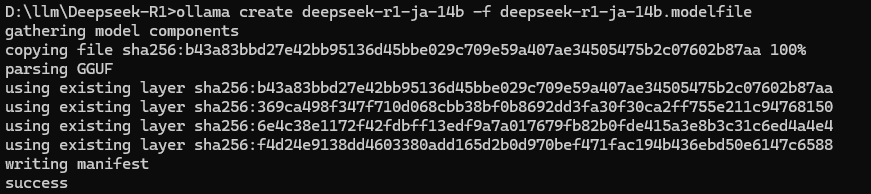
参考記事の動作確認問題を実行する
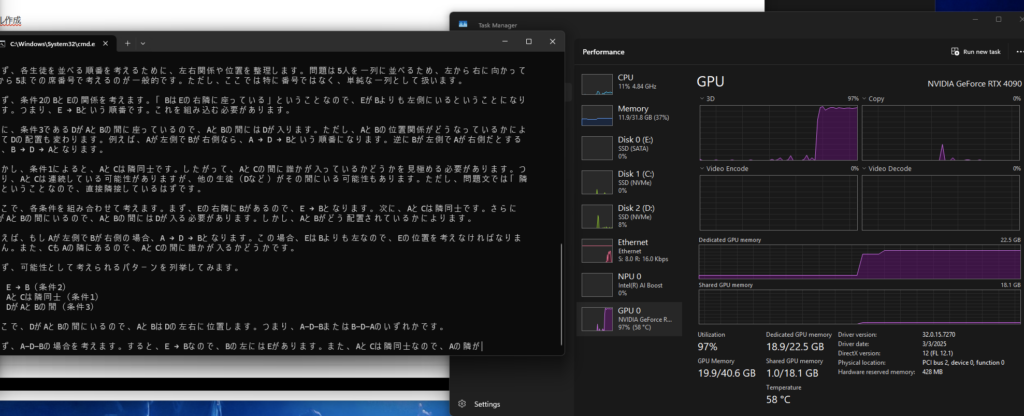
30分ぐらいかかってできた。すごい遅い気がするけど、Prologとかと違って自力で答え出せるのやはりいいね。

vscode+clineだと、14bのみスクラッチC++で結構惜しいところまでコーディングを自力完遂できた。32bはどの量子ビットもAPIエラーになるので、わからん。
llama.cpp gguf のファイル名の意味


よって、Q4_K_M から試す感じでよさげ。
記憶力がなんでか弱い気がするけど、「cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-Q4_K_M.gguf」が軽量高速でいい感じ。ギリギリ、12GB VRAMで動くかも?RTX4090は余裕でVRAMに収まってて、文章の生成速度が会社で使ってるGPT-4oより速い。
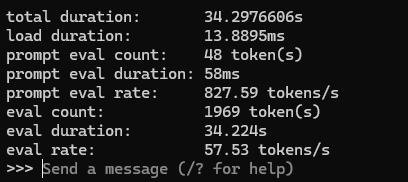

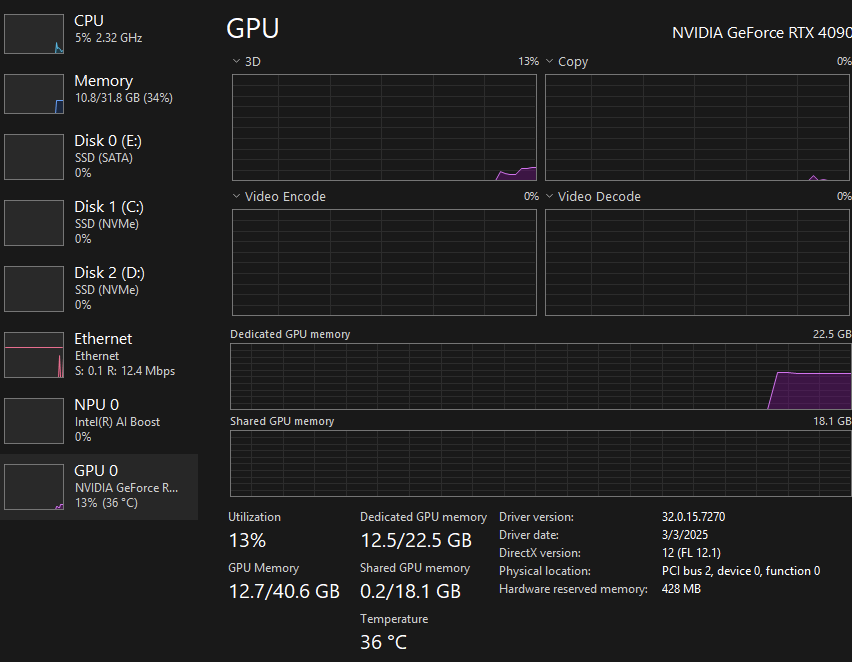
QwQ-32B

QwQのサイト自身でollama runそのままできるらしいので実行。
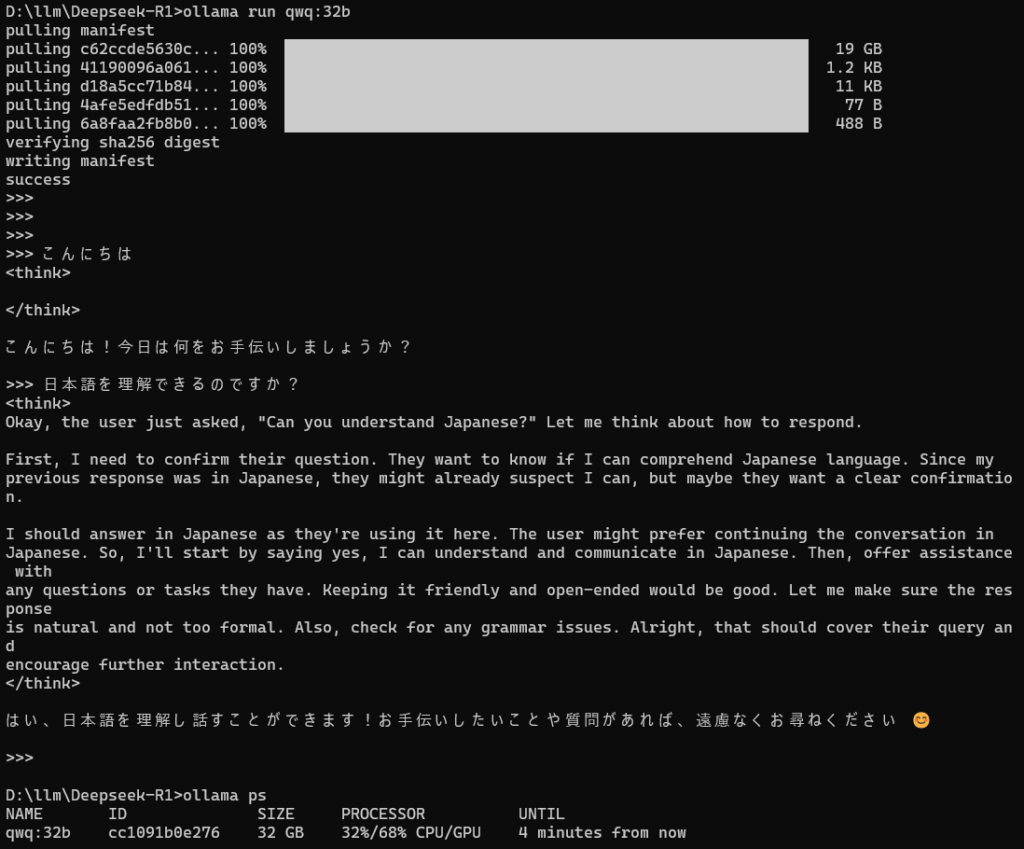
なんか端折られてる気がするものの、標準モデルのまま日本語理解してくれる。Cyberagentカスタム版待たなくてもよさげ ※どこがカスタムされてんのか知らないけど。

コメント